AI Crawler Access
Shopify robots.txt for AI Crawlers
A practical guide to Shopify robots.txt, AI crawler access, private paths, Googlebot risk, and monitoring for agentic shopping visibility.

AI shopping systems cannot recommend what they cannot crawl, read, or trust. For Shopify stores, robots.txt is one of the first gates between your product catalog and search engines, AI assistants, shopping agents, and commercial crawlers.
The goal is not to allow everything. The goal is to keep important product, collection, image, and structured data paths accessible while protecting cart, checkout, account, search, filter, and internal utility paths that do not help discovery.
Robots.txt controls crawling, not content quality
Robots.txt tells compliant crawlers which paths they should not request. It does not add product schema, fix duplicate variants, improve thin descriptions, or guarantee indexing. Treat it as access control for crawlers, not as a substitute for technical SEO.
What Shopify usually handles well by default
Keep these defaults unless you have a clear reason
- check_circleProduct and collection pages should remain crawlable.
- check_circleStatic assets needed to render product content should remain crawlable.
- check_circleCart, checkout, account, and internal search paths usually do not need crawler access.
- check_circleSitemap paths should remain discoverable.
- check_circleGooglebot should not be blocked unless you intentionally want to remove Google Search access.
A sane AI crawler policy for Shopify
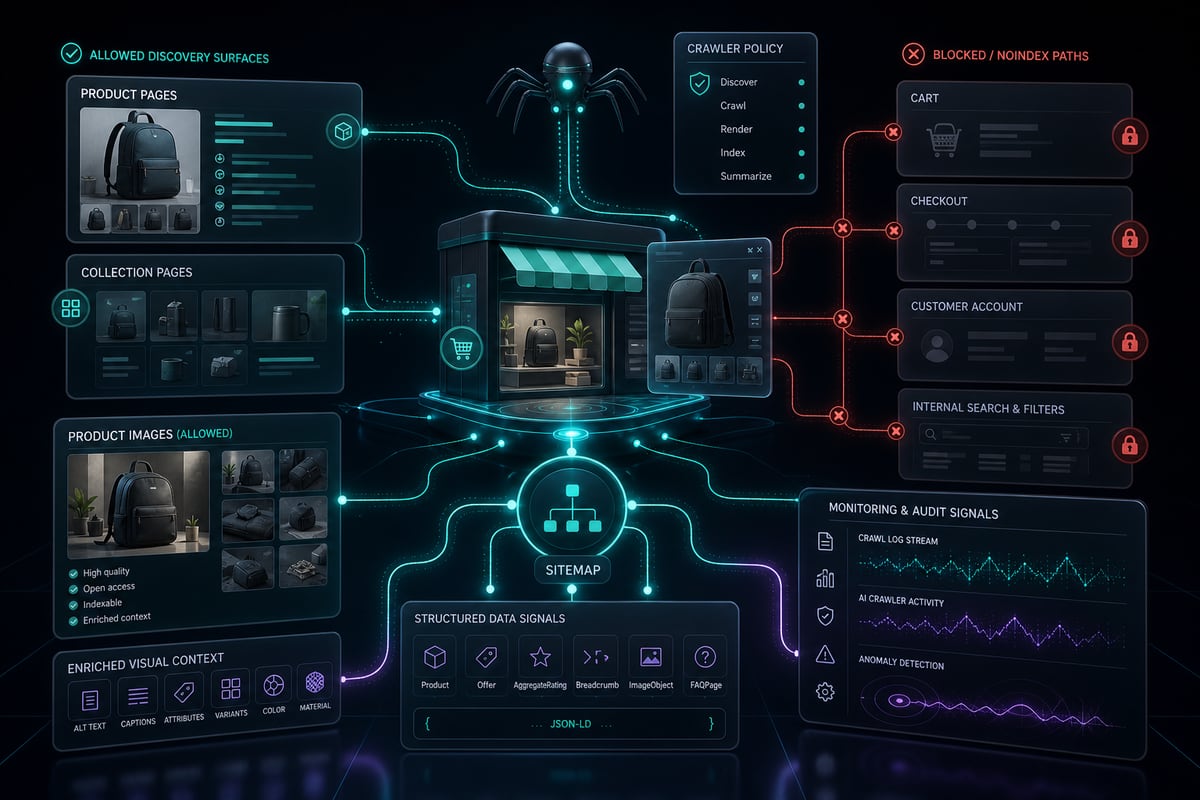
For a growth-stage ecommerce site, a balanced policy is usually better than a blanket block. Allow crawlers that can create discovery value, protect private and low-value paths, and monitor logs or CDN analytics for abnormal traffic.
A sane AI crawler policy for Shopify
| Path type | Recommended policy | Why it matters |
|---|---|---|
| Product pages | Allow | They contain the commercial facts AI shopping systems need. |
| Collection pages | Allow | They help crawlers understand categories, inventory groupings, and internal links. |
| Product images | Allow | Images support visual search, previews, and richer product understanding. |
| Cart and checkout | Disallow | They do not help discovery and may create crawl waste. |
| Customer account pages | Disallow | They are private or low-value for public discovery. |
| Internal search and filtered URLs | Usually disallow | They can create duplicate or infinite crawl paths. |
| Sitemap | Allow | It helps crawlers find canonical URLs efficiently. |
Example Shopify robots.txt rules for AI crawlers
Shopify stores can customize robots rules through the theme's robots.txt.liquid template. Keep custom rules small, documented, and easy to reverse. Do not copy a crawler blocklist blindly from another store.
User-agent: *
Disallow: /cart
Disallow: /checkout
Disallow: /account
Disallow: /search
Disallow: /*?*sort_by=
Disallow: /*?*filter.
User-agent: Googlebot
Allow: /
User-agent: GPTBot
Disallow: /cart
Disallow: /checkout
Disallow: /account
User-agent: Google-Extended
Disallow: /Google-Extended is not the same as Googlebot
Google-Extended is a separate control for certain Google AI training and product use cases. Blocking Google-Extended is different from blocking Googlebot. If your priority is Search visibility, never treat them as interchangeable.
What to monitor after changing robots.txt
Post-change checks
- 1Open /robots.txt and confirm the final rendered file is what you expected.
- 2Verify product and collection URLs are not blocked for Googlebot.
- 3Check sitemap URLs are still accessible.
- 4Run a crawler access check against representative product pages.
- 5Watch server, CDN, or Shopify analytics for crawl spikes.
- 6Keep a dated note of every robots.txt change so you can roll back quickly.
Common Shopify robots.txt mistakes
Common Shopify robots.txt mistakes
- errorBlocking all query parameters when important variant URLs depend on parameters.
- errorBlocking image folders needed for product previews.
- errorBlocking Googlebot while trying to block only AI training crawlers.
- errorAssuming robots.txt can fix duplicate content by itself.
- errorForgetting that some crawlers may ignore robots.txt or use changing user-agent strings.
FAQ
Should Shopify stores block AI crawlers?keyboard_arrow_down
Not by default. If AI shopping visibility matters, allow crawler access to public product and collection pages while blocking private or low-value paths such as cart, checkout, account, search, and duplicate filters.
Can robots.txt remove Shopify product pages from Google?keyboard_arrow_down
Robots.txt controls crawling. If Google already knows a URL, blocking crawl is not the same as a clean noindex strategy. For Google Search, be especially careful not to block Googlebot from important product pages.
Does Shopify allow robots.txt customization?keyboard_arrow_down
Yes, Shopify supports robots.txt customization through the theme's robots.txt.liquid template. Keep changes conservative and test the rendered /robots.txt file after publishing.
Which Shopify URLs should stay crawlable for AI shopping?keyboard_arrow_down
Product pages, collection pages, product images, canonical URLs, and sitemap URLs should usually remain crawlable because they carry product facts, category context, and discovery links.
Article funnel
Turn this article into a product-page check
Primary search intent
Confirm that search and AI crawlers can reach the product facts the article depends on.
Use the matching ShopGox scanner to verify the issue on a real product URL, then use the related hub and example report for implementation context.
What to check
- rulerobots.txt, meta robots, canonical tags, HTTP status, and rendered HTML access for important product URLs.
- ruleWhether Googlebot, GPTBot, and other AI crawlers can reach product title, price, availability, images, and schema.
- ruleWhether storefront protection, app scripts, consent banners, or geofencing hide product facts from crawlers.
How to verify
- fact_checkRun the AI crawler access checker on a public product page.
- fact_checkReview crawler access, rendered facts, and schema findings before changing robots rules.
- fact_checkUse the topic hub and example report to separate crawl blocking from schema or content quality issues.
Common mistakes
- warningAllowing a bot in robots.txt while blocking the same content with meta robots, canonical drift, or storefront protection.
- warningTesting only the homepage instead of the actual product URL.
- warningTreating crawler access as solved when product facts still render too late or inconsistently.
Related tools
AI Crawler Access Checker for Ecommerce Product Pages
Check product pages for Googlebot, GPTBot, OAI-SearchBot, ClaudeBot, PerplexityBot, robots.txt, noindex, sitemap, canonical, and rendered access issues.
AI Shopping Readiness Scanner for Ecommerce Stores
Scan ecommerce product pages for AI search readiness, Product schema, crawler access signals, product attributes, semantic clarity, and structured data consistency.
Shopify SEO Checker for Product Pages, Variants, Markets, and AI Shopping
Free Shopify SEO checker for product pages, variant schema, theme Liquid, SEO apps, review apps, Markets currency, hreflang, and AI shopping readiness.
Free Shopify Schema Checker for Product Pages
Scan Shopify product pages for Product schema, variant Offers, review app markup, theme conflicts, Shopify Markets signals, and AI search readiness.
Related posts
Product Page SEO Audit Checklist for Ecommerce
A complete product page audit checklist for ecommerce SEO, structured data, AI shopping visibility, and conversion-focused content.
Shopify Agentic Commerce Readiness Checklist
A practical checklist for making Shopify product pages easier for AI shoppers and buying agents to understand, compare, and recommend.
How to Add Product Schema in Shopify
A practical Shopify guide to adding Product and Offer JSON-LD without creating conflicts with themes, SEO apps, review apps, variants, or Markets.