Accesso dei crawler AI
Shopify robots.txt per crawler AI
Una guida pratica a Shopify robots.txt, accesso al crawler AI, percorsi privati, rischio di Googlebot e monitoraggio della visibilità degli acquisti degli agenti.

I sistemi di acquisto AI non possono consigliare ciò di cui non possono scansionare, leggere o fidarsi. Per i negozi Shopify, robots.txt è una delle prime porte tra il catalogo dei prodotti e i motori di ricerca, gli assistenti AI, gli agenti degli acquisti e i crawler commerciali.
L'obiettivo non è permettere tutto. L'obiettivo è mantenere accessibili i percorsi importanti di prodotti, raccolte, immagini e dati strutturati, proteggendo al contempo i percorsi di carrello, pagamento, account, ricerca, filtro e utilità interna che non aiutano la scoperta.
Robots.txt controlla la scansione, non la qualità dei contenuti
Robots.txt indica ai crawler conformi quali percorsi non devono richiedere. It does not add product schema, fix duplicate variants, improve thin descriptions, or guarantee indexing. Consideralo come un controllo di accesso per i crawler, non come un sostituto del SEO tecnico.
Ciò che Shopify di solito gestisce bene per impostazione predefinita
Mantieni queste impostazioni predefinite a meno che tu non abbia una ragione chiara
- check_circleLe pagine dei prodotti e delle collezioni devono rimanere sottoponibili a scansione.
- check_circleLe risorse statiche necessarie per il rendering dei contenuti del prodotto devono rimanere sottoponibili a scansione.
- check_circleCarrello, pagamento, account e percorsi di ricerca interni di solito non necessitano dell'accesso del crawler.
- check_circleI percorsi della mappa del sito dovrebbero rimanere rilevabili.
- check_circleGooglebot non deve essere bloccato a meno che tu non voglia rimuovere intenzionalmente l'accesso alla Ricerca Google.
Una sana politica di crawler AI per Shopify
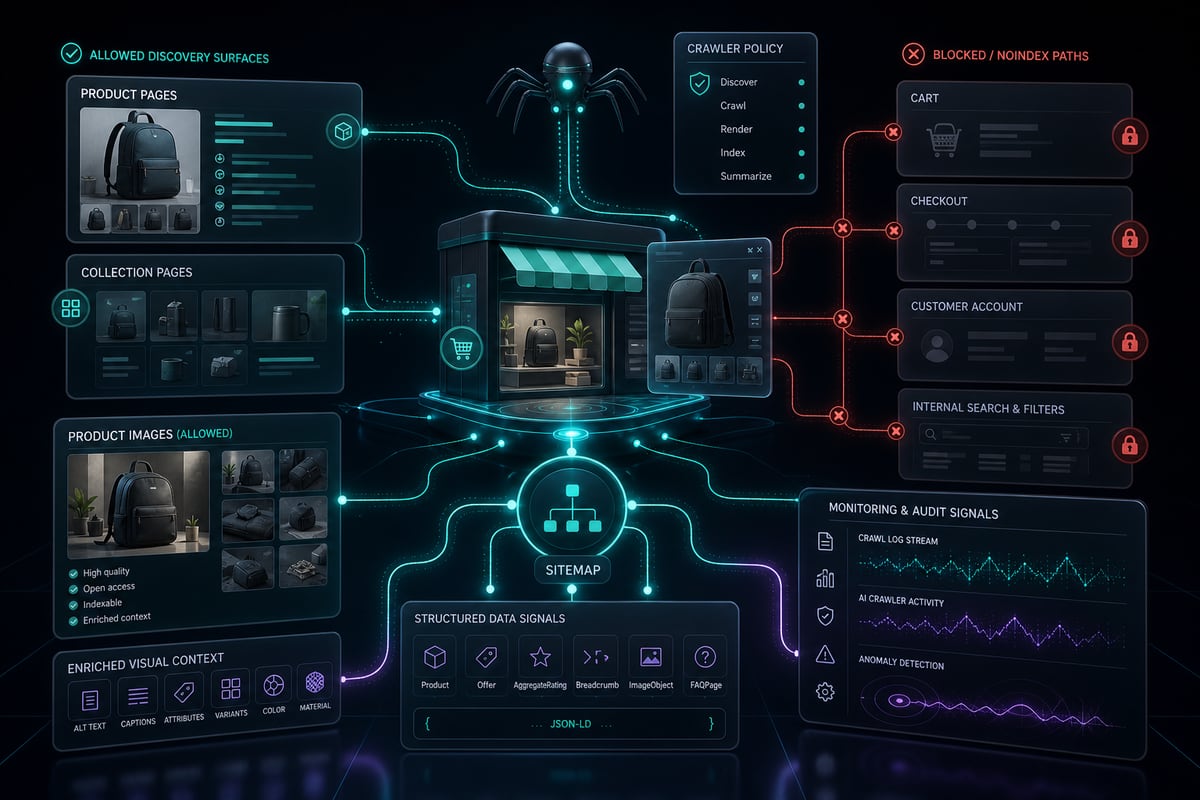
Per un sito di e-commerce in fase di crescita, una politica equilibrata è solitamente migliore di un blocco generalizzato. Consenti ai crawler di creare valore di rilevamento, proteggere percorsi privati e di basso valore e monitorare i log o le analisi CDN per rilevare traffico anomalo.
Una sana politica di crawler AI per Shopify
| Tipo di percorso | Politica consigliata | Perché è importante |
|---|---|---|
| Pagine dei prodotti | Consenti | Contengono i fatti commerciali di cui i sistemi di acquisto AI hanno bisogno. |
| Pagine di raccolta | Consenti | Aiutano i crawler a comprendere categorie, raggruppamenti di inventario e collegamenti interni. |
| Immagini del prodotto | Consenti | Le immagini supportano la ricerca visiva, le anteprime e una comprensione più approfondita del prodotto. |
| Carrello e pagamento | Non consentire | Non aiutano la scoperta e possono creare rifiuti di scansione. |
| Pagine dell'account cliente | Non consentire | Sono privati o di basso valore per la scoperta pubblica. |
| Ricerca interna e URL filtrati | Normalmente non consentito | Possono creare percorsi di scansione duplicati o infiniti. |
| Mappa del sito | Consenti | Aiuta i crawler a trovare gli URL canonici in modo efficiente. |
Esempio di regole Shopify robots.txt per crawler AI
I negozi Shopify possono personalizzare le regole dei robot tramite il modello robots.txt.liquid del tema. Mantieni le regole personalizzate piccole, documentate e facili da annullare. Non copiare ciecamente una blocklist del crawler da un altro negozio.
User-agent: *
Disallow: /cart
Disallow: /checkout
Disallow: /account
Disallow: /search
Disallow: /*?*sort_by=
Disallow: /*?*filter.
User-agent: Googlebot
Allow: /
User-agent: GPTBot
Disallow: /cart
Disallow: /checkout
Disallow: /account
User-agent: Google-Extended
Disallow: /Google-Extended non è la stessa cosa di Googlebot
Google-Extended è un controllo separato per determinati casi di utilizzo dei prodotti e della formazione sull'intelligenza artificiale di Google. Bloccare Google-Extended è diverso dal bloccare Googlebot. Se la tua priorità è la visibilità nella Ricerca, non trattarli mai come intercambiabili.
Cosa monitorare dopo aver modificato robots.txt
Controlli post-modifica
- 1Apri /robots.txt e conferma che il file renderizzato finale è quello previsto.
- 2Verifica che gli URL del prodotto e della raccolta non siano bloccati per Googlebot.
- 3Verifica che gli URL della mappa del sito siano ancora accessibili.
- 4Esegui un controllo di accesso del crawler rispetto alle pagine di prodotto rappresentative.
- 5Controlla l'analisi dei server, della CDN o di Shopify per individuare eventuali picchi di scansione.
- 6Mantieni una nota con la data di ogni modifica al file robots.txt in modo da poter tornare indietro rapidamente.
Errori comuni di Shopify robots.txt
Errori comuni di Shopify robots.txt
- errorBlocco di tutti i parametri di query quando varianti URL importanti dipendono dai parametri.
- errorBlocco delle cartelle di immagini necessarie per le anteprime dei prodotti.
- errorBlocco di Googlebot mentre si tenta di bloccare solo i crawler di addestramento dell'IA.
- errorSupponendo che robots.txt possa correggere da solo i contenuti duplicati.
- errorDimenticare che alcuni crawler potrebbero ignorare robots.txt o utilizzare stringhe user-agent modificabili.
FAQ
I negozi Shopify dovrebbero bloccare i crawler AI?keyboard_arrow_down
Non per impostazione predefinita. Se la visibilità degli acquisti tramite l'intelligenza artificiale è importante, consenti l'accesso del crawler alle pagine pubbliche di prodotti e collezioni bloccando percorsi privati o di basso valore come carrello, pagamento, account, ricerca e filtri duplicati.
Robots.txt può rimuovere le pagine dei prodotti Shopify da Google?keyboard_arrow_down
Robots.txt controlla la scansione. Se Google conosce già un URL, bloccare la scansione non è la stessa cosa di una strategia noindex pulita. Per Ricerca Google, presta particolare attenzione a non impedire a Googlebot di accedere a pagine di prodotti importanti.
Shopify consente la personalizzazione del file robots.txt?keyboard_arrow_down
Sì, Shopify supporta la personalizzazione del file robots.txt tramite il modello robots.txt.liquid del tema. Mantieni le modifiche conservatrici e testa il file /robots.txt renderizzato dopo la pubblicazione.
Quali URL di Shopify dovrebbero rimanere scansionabili per lo shopping AI?keyboard_arrow_down
Le pagine dei prodotti, le pagine delle collezioni, le immagini dei prodotti, gli URL canonici e gli URL delle mappe dei siti dovrebbero in genere rimanere sottoponibili a scansione perché contengono informazioni sui prodotti, contesto di categoria e collegamenti di scoperta.
Strumenti correlati
AI Controllo accesso crawler per e-commerce Product Pagine
Controlla le pagine dei prodotti e-commerce per l'accesso del crawler a AI, le regole robots.txt, i meta robot, X-Robots-Tag, la scoperta della mappa del sito, i segnali canonical e la disponibilità della ricerca AI.
Scanner di preparazione allo shopping AI per negozi di e-commerce
Scansiona le pagine dei prodotti e-commerce per verificare la disponibilità della ricerca AI, lo schema del prodotto, i segnali di accesso del crawler, gli attributi del prodotto, la chiarezza semantica e la coerenza dei dati strutturati.
Scansiona le pagine dei prodotti Shopify per verificare la disponibilità della ricerca SEO e AI
Scanner gratuito delle pagine dei prodotti Shopify per conflitti di schemi, dati sulle varianti, metadati inseriti nell'app, hreflang di Markets e disponibilità della ricerca AI.
Controllo schema Shopify per le pagine dei prodotti
Controllo gratuito dello schema Shopify per le pagine dei prodotti. Scansione dello schema del prodotto, delle offerte di varianti, dei metadati inseriti nell'app, dei segnali di Shopify Markets e della disponibilità della ricerca AI.
Post correlati
Elenco di controllo per il controllo SEO della pagina prodotto per l'e-commerce
Un elenco di controllo completo delle pagine di prodotto per SEO e-commerce, dati strutturati, visibilità degli acquisti tramite intelligenza artificiale e contenuti incentrati sulle conversioni.
Elenco di controllo per la preparazione al commercio di Shopify Agentic
Una pratica lista di controllo per rendere le pagine dei prodotti Shopify più facili da comprendere, confrontare e consigliare per gli acquirenti e gli agenti di acquisto dotati di intelligenza artificiale.
Come aggiungere lo schema del prodotto in Shopify
Una pratica guida Shopify per aggiungere prodotti e offerte JSON-LD senza creare conflitti con temi, app SEO, app di recensioni, varianti o mercati.