Zugriff für KI-Crawler
Shopify robots.txt für KI-Crawler
Ein praktischer Leitfaden zu Shopify robots.txt, KI-Crawler-Zugriff, privaten Pfaden, Googlebot-Risiko und Überwachung der Agenten-Shopping-Sichtbarkeit.

KI-Shopping-Systeme können nicht empfehlen, was sie nicht crawlen, lesen oder denen sie nicht vertrauen können. Für Shopify-Shops ist robots.txt eines der ersten Tore zwischen Ihrem Produktkatalog und Suchmaschinen, KI-Assistenten, Shopping-Agenten und kommerziellen Crawlern.
Das Ziel ist nicht, alles zuzulassen. Das Ziel besteht darin, wichtige Produkt-, Sammlungs-, Bild- und strukturierte Datenpfade zugänglich zu halten und gleichzeitig Warenkorb-, Kassen-, Konto-, Such-, Filter- und interne Dienstprogrammpfade zu schützen, die nicht zur Entdeckung beitragen.
Robots.txt steuert das Crawlen, nicht die Inhaltsqualität
Robots.txt teilt konformen Crawlern mit, welche Pfade sie nicht anfordern sollen. Es fügt kein Produktschema hinzu, korrigiert keine doppelten Varianten, verbessert dünne Beschreibungen und garantiert keine Indizierung. Behandeln Sie es als Zugriffskontrolle für Crawler und nicht als Ersatz für technisches SEO.
Was Shopify normalerweise standardmäßig gut beherrscht
Behalten Sie diese Standardeinstellungen bei, es sei denn, Sie haben einen klaren Grund
- check_circleProdukt- und Sammlungsseiten sollten crawlbar bleiben.
- check_circleStatische Assets, die zum Rendern von Produktinhalten benötigt werden, sollten weiterhin crawlbar sein.
- check_circleWarenkorb, Kasse, Konto und interne Suchpfade benötigen normalerweise keinen Crawler-Zugriff.
- check_circleSitemap-Pfade sollten erkennbar bleiben.
- check_circleGooglebot sollte nicht blockiert werden, es sei denn, Sie möchten den Zugriff auf die Google-Suche absichtlich entfernen.
Eine vernünftige KI-Crawler-Richtlinie für Shopify
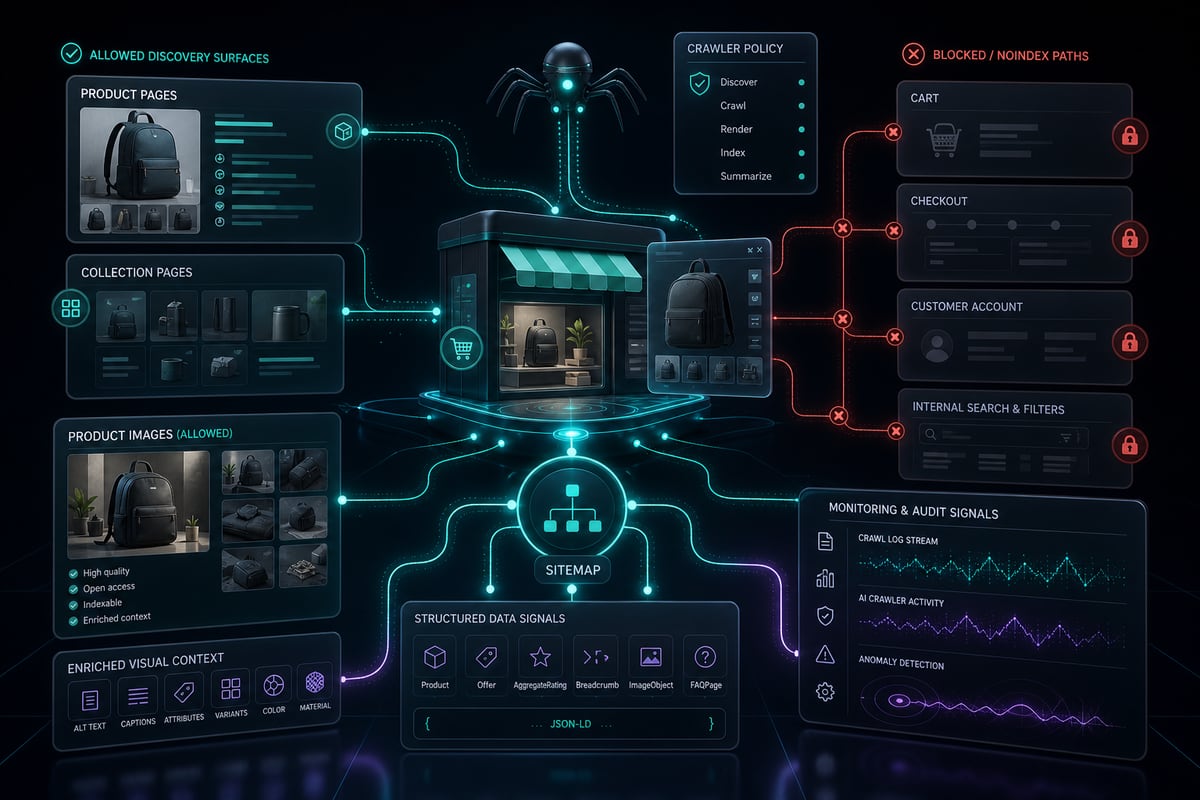
Für eine E-Commerce-Website in der Wachstumsphase ist eine ausgewogene Richtlinie normalerweise besser als eine pauschale Sperrung. Erlauben Sie Crawlern, die einen Entdeckungswert schaffen, private und geringwertige Pfade schützen und Protokolle oder CDN-Analysen auf ungewöhnlichen Datenverkehr überwachen können.
Eine vernünftige KI-Crawler-Richtlinie für Shopify
| Pfadtyp | Empfohlene Richtlinie | Warum es wichtig ist |
|---|---|---|
| Produktseiten | Zulassen | Sie enthalten die kommerziellen Fakten, die KI-Shopping-Systeme benötigen. |
| Sammlungsseiten | Zulassen | Sie helfen Crawlern, Kategorien, Inventargruppierungen und interne Links zu verstehen. |
| Produktbilder | Zulassen | Bilder unterstützen die visuelle Suche, Vorschauen und ein umfassenderes Produktverständnis. |
| Warenkorb und Kasse | Nicht zulassen | Sie helfen nicht bei der Entdeckung und können zu Crawling-Verschwendung führen. |
| Kundenkontoseiten | Nicht zulassen | Sie sind privat oder von geringem Wert für die öffentliche Entdeckung. |
| Interne Suche und gefilterte URLs | Normalerweise nicht zulassen | Sie können doppelte oder unendliche Crawling-Pfade erstellen. |
| Sitemap | Zulassen | Es hilft Crawlern, kanonische URLs effizient zu finden. |
Beispiel für Shopify robots.txt-Regeln für KI-Crawler
Shopify-Shops können Robots-Regeln über die robots.txt.liquid-Vorlage des Themes anpassen. Halten Sie benutzerdefinierte Regeln klein, dokumentiert und leicht rückgängig zu machen. Kopieren Sie eine Crawler-Blocklist nicht blind aus einem anderen Store.
User-agent: *
Disallow: /cart
Disallow: /checkout
Disallow: /account
Disallow: /search
Disallow: /*?*sort_by=
Disallow: /*?*filter.
User-agent: Googlebot
Allow: /
User-agent: GPTBot
Disallow: /cart
Disallow: /checkout
Disallow: /account
User-agent: Google-Extended
Disallow: /Google-Extended ist nicht dasselbe wie Googlebot
Google-Extended ist eine separate Steuerung für bestimmte Google AI-Trainings- und Produktanwendungsfälle. Das Blockieren von Google-Extended unterscheidet sich vom Blockieren des Googlebot. Wenn die Sichtbarkeit in der Suche für Sie Priorität hat, sollten Sie sie niemals als austauschbar betrachten.
Was nach der Änderung von robots.txt zu überwachen ist
Prüfungen nach der Änderung
- 1Öffnen Sie /robots.txt und bestätigen Sie, dass die endgültige gerenderte Datei Ihren Erwartungen entspricht.
- 2Stellen Sie sicher, dass Produkt- und Sammlungs-URLs nicht für den Googlebot blockiert sind.
- 3Überprüfen Sie, ob Sitemap-URLs weiterhin zugänglich sind.
- 4Führen Sie eine Crawler-Zugriffsprüfung anhand repräsentativer Produktseiten durch.
- 5Beobachten Sie Server-, CDN- oder Shopify-Analysen auf Crawling-Spitzen.
- 6Notieren Sie sich jede robots.txt-Änderung mit Datum, damit Sie sie schnell rückgängig machen können.
Häufige Shopify robots.txt-Fehler
Häufige Shopify robots.txt-Fehler
- errorBlockieren aller Abfrageparameter, wenn wichtige Varianten-URLs von Parametern abhängen.
- errorBlockieren von Bildordnern, die für Produktvorschauen benötigt werden.
- errorGooglebot wird blockiert, während versucht wird, nur KI-Trainingscrawler zu blockieren.
- errorVorausgesetzt, robots.txt kann doppelte Inhalte selbst reparieren.
- errorVergessen Sie, dass einige Crawler möglicherweise robots.txt ignorieren oder sich ändernde Benutzeragentenzeichenfolgen verwenden.
FAQ
Sollten Shopify-Shops KI-Crawler blockieren?keyboard_arrow_down
Nicht standardmäßig. Wenn die Sichtbarkeit von KI-Einkäufen wichtig ist, erlauben Sie dem Crawler Zugriff auf öffentliche Produkt- und Kollektionsseiten und blockieren Sie gleichzeitig private oder geringwertige Pfade wie Warenkorb, Kasse, Konto, Suche und Duplikatfilter.
Kann robots.txt Shopify-Produktseiten von Google entfernen?keyboard_arrow_down
Robots.txt steuert das Crawlen. Wenn Google bereits eine URL kennt, ist das Blockieren des Crawls nicht dasselbe wie eine saubere Noindex-Strategie. Achten Sie bei der Google-Suche besonders darauf, den Googlebot nicht von wichtigen Produktseiten zu blockieren.
Ermöglicht Shopify die Anpassung von robots.txt?keyboard_arrow_down
Ja, Shopify unterstützt die robots.txt-Anpassung über die robots.txt.liquid-Vorlage des Themes. Halten Sie die Änderungen konservativ und testen Sie die gerenderte Datei /robots.txt nach der Veröffentlichung.
Welche Shopify-URLs sollten für KI-Shopping crawlbar bleiben?keyboard_arrow_down
Produktseiten, Sammlungsseiten, Produktbilder, kanonische URLs und Sitemap-URLs sollten normalerweise crawlbar bleiben, da sie Produktfakten, Kategoriekontext und Entdeckungslinks enthalten.
Verwandte Tools
AI Crawler-Zugriffsprüfung für E-Commerce Product Seiten
Überprüfen Sie die E-Commerce-Produktseiten auf AI-Crawler-Zugriff, robots.txt-Regeln, Meta-Robots, X-Robots-Tag, Sitemap-Erkennung, canonical-Signale und AI-Suchbereitschaft.
KI-Shopping-Readiness-Scanner für E-Commerce-Shops
Scannen Sie E-Commerce-Produktseiten auf KI-Suchbereitschaft, Produktschema, Crawler-Zugriffssignale, Produktattribute, semantische Klarheit und Konsistenz strukturierter Daten.
Shopify SEO Checker für Produktseiten, Varianten, Markets und KI-Shopping
Kostenloser Shopify SEO Checker für Produktseiten, Variantenschema, Theme Liquid, SEO-Apps, Reviews, Markets, hreflang und KI-Shopping.
Shopify Schema Checker für Produktseiten
Kostenloser Shopify-Schema-Checker für Produktseiten. Scannen Sie Produktschema, Variantenangebote, App-injizierte Metadaten, Shopify Markets-Signale und KI-Suchbereitschaft.
Verwandte Beiträge
Produktseiten-SEO-Audit-Checkliste für E-Commerce
Eine vollständige Produktseiten-Audit-Checkliste für E-Commerce-SEO, strukturierte Daten, KI-Shopping-Sichtbarkeit und konvertierungsorientierte Inhalte.
Shopify Agentic Commerce Readiness Checkliste
Eine praktische Checkliste, um Shopify-Produktseiten für KI-Käufer und Einkäufer einfacher zu verstehen, zu vergleichen und zu empfehlen.
So fügen Sie ein Produktschema in Shopify hinzu
Eine praktische Shopify-Anleitung zum Hinzufügen von Produkt- und Angebots-JSON-LD, ohne Konflikte mit Themen, SEO-Apps, Bewertungs-Apps, Varianten oder Märkten zu verursachen.