AI 爬虫访问
适用于 AI 爬虫的 Shopify robots.txt
Shopify robots.txt、AI 抓取工具访问、私有路径、Googlebot 风险以及代理购物可见性监控的实用指南。

人工智能购物系统无法推荐他们无法抓取、阅读或信任的商品。对于 Shopify 商店,robots.txt 是产品目录与搜索引擎、人工智能助手、购物代理和商业爬虫之间的首要门户之一。
我们的目标不是允许一切。目标是保持重要的产品、集合、图像和结构化数据路径可访问,同时保护购物车、结帐、帐户、搜索、过滤器和无助于发现的内部实用程序路径。
Robots.txt 控制抓取,而不是内容质量
Robots.txt 告诉合规爬虫它们不应请求哪些路径。它不会添加产品架构、修复重复变体、改进精简描述或保证索引。将其视为爬虫的访问控制,而不是技术 SEO 的替代品。
默认情况下 Shopify 通常可以很好地处理哪些内容
保留这些默认设置,除非有明确的原因
- check_circle产品和产品系列页面应保持可抓取状态。
- check_circle呈现产品内容所需的静态资源应保持可抓取状态。
- check_circle购物车、结帐、帐户和内部搜索路径通常不需要抓取工具访问权限。
- check_circle站点地图路径应保持可发现性。
- check_circle除非您有意删除 Google 搜索访问权限,否则不应阻止 Googlebot。
Shopify 的合理 AI 抓取工具策略
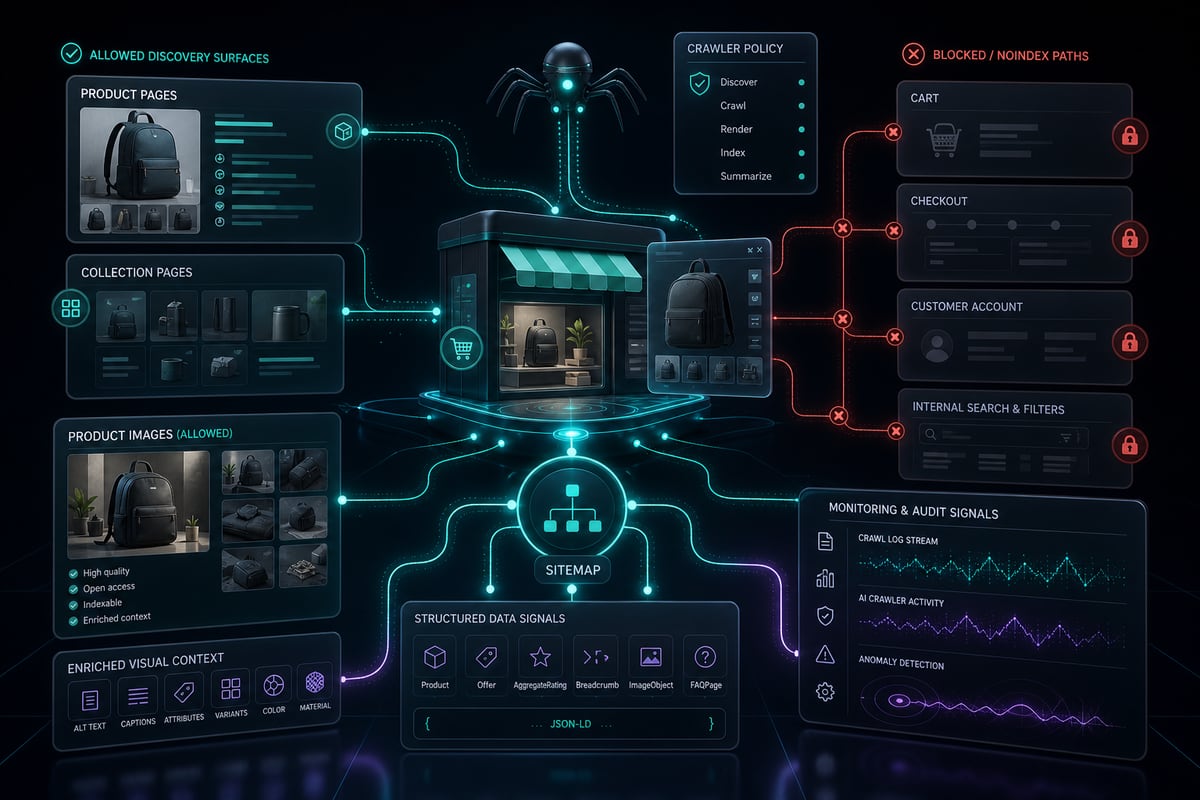
对于成长阶段的电子商务网站来说,平衡的政策通常比一揽子封锁更好。允许爬虫能够创造发现价值、保护私有和低价值路径以及监控日志或 CDN 分析以发现异常流量。
Shopify 的合理 AI 抓取工具策略
| 路径类型 | 推荐政策 | 为什么它很重要 |
|---|---|---|
| 产品页面 | 允许 | 它们包含人工智能购物系统所需的商业事实。 |
| 收藏页面 | 允许 | 它们帮助抓取工具了解类别、库存分组和内部链接。 |
| 产品图片 | 允许 | 图像支持视觉搜索、预览和更丰富的产品理解。 |
| 购物车和结账 | 禁止 | 它们无助于发现,并且可能会造成抓取浪费。 |
| 客户帐户页面 | 禁止 | 它们是私有的或对于公众发现而言价值较低。 |
| 内部搜索和过滤的网址 | 通常不允许 | 他们可以创建重复或无限的抓取路径。 |
| 站点地图 | 允许 | 它可以帮助爬虫有效地找到规范的网址。 |
AI 抓取工具的 Shopify robots.txt 规则示例
Shopify 商店可以通过主题的 robots.txt.liquid 模板自定义机器人规则。保持自定义规则较小、记录在案且易于撤销。不要盲目地从其他商店复制爬虫阻止列表。
User-agent: *
Disallow: /cart
Disallow: /checkout
Disallow: /account
Disallow: /search
Disallow: /*?*sort_by=
Disallow: /*?*filter.
User-agent: Googlebot
Allow: /
User-agent: GPTBot
Disallow: /cart
Disallow: /checkout
Disallow: /account
User-agent: Google-Extended
Disallow: /Google 扩展与 Googlebot 不同
Google-Extended 是针对某些 Google AI 培训和产品用例的单独控件。阻止 Google-Extend 与阻止 Googlebot 不同。如果您的首要任务是搜索可见性,切勿将它们视为可互换的。
更改 robots.txt 后要监控的内容
更改后检查
- 1打开 /robots.txt 并确认最终渲染的文件符合您的预期。
- 2验证 Googlebot 没有屏蔽产品和产品系列网址。
- 3检查站点地图网址是否仍可访问。
- 4针对代表性产品页面运行抓取工具访问检查。
- 5观察服务器、CDN 或 Shopify 分析以了解抓取峰值。
- 6为 robots.txt 的每项更改保留注明日期的注释,以便您可以快速回滚。
常见的 Shopify robots.txt 错误
常见的 Shopify robots.txt 错误
- error当重要的变体 URL 依赖于参数时,阻止所有查询参数。
- error阻止产品预览所需的图像文件夹。
- error阻止 Googlebot,同时尝试仅阻止 AI 训练抓取工具。
- error假设 robots.txt 可以自行修复重复内容。
- error忘记某些抓取工具可能会忽略 robots.txt 或使用更改的用户代理字符串。
常见问题
Shopify 商店应该阻止 AI 爬虫吗?keyboard_arrow_down
默认情况下不是。如果人工智能购物可见性很重要,请允许爬虫访问公共产品和产品系列页面,同时阻止私有或低价值路径,例如购物车、结帐、帐户、搜索和重复过滤器。
robots.txt 能否从 Google 中删除 Shopify 产品页面?keyboard_arrow_down
Robots.txt 控制抓取。如果 Google 已经知道某个 URL,则阻止抓取与干净的 noindex 策略不同。对于 Google 搜索,请特别小心,不要阻止 Googlebot 访问重要的产品页面。
Shopify 是否允许 robots.txt 自定义?keyboard_arrow_down
是的,Shopify 支持通过主题的 robots.txt.liquid 模板进行 robots.txt 自定义。保持更改保守并在发布后测试渲染的 /robots.txt 文件。
哪些 Shopify 网址应保持可抓取以供 AI 购物使用?keyboard_arrow_down
产品页面、产品系列页面、产品图片、规范 URL 和站点地图 URL 通常应保持可抓取状态,因为它们包含产品事实、类别上下文和发现链接。
相关工具
AI Crawler Access Checker:检查电商产品页的爬虫访问
检查电商产品页的 AI crawler access、robots.txt 规则、meta robots、X-Robots-Tag、sitemap 发现、canonical 信号和 AI 搜索可见性风险。
适用于电子商务商店的 AI 购物准备扫描器
扫描电子商务产品页面,了解 AI 搜索准备情况、产品 Schema、爬虫访问信号、产品属性、语义清晰度和结构化数据一致性。
Shopify SEO 检查器:产品页、变体、Markets 和 AI 购物
免费的 Shopify SEO 检查器,用于产品页、变体 schema、主题 Liquid、SEO 应用、评论应用、Markets 货币、hreflang 和 AI 购物就绪度。
产品页面的 Shopify Schema 检查器
产品页面的免费 Shopify Schema 检查器。扫描产品 Schema、变体报价、应用程序注入的元数据、Shopify Markets 信号和 AI 搜索准备情况。